xython_regex
xy_re(예제) – 추출하기 - 07
작성자
sjpark
작성일
2025-01-08 19:29
조회
101
예제 - 영어나 숫자로 시작한 글자들만 추출하기
어디선가 자료를 갖고와보면 숫자번호가 메겨져있는 자료들이 있다 이것을 없애고 싶은 경우가 많다
위와 같은 자료가 있을 때 변경하는 것을 보여드립니다
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_list = [
["2. 예제용 2번입니다"],
["3. 예제용 3번입니다"],
["4. 예제용 4번입니다"],
["5. 예제용 5번입니다"],
["6. 예제용 6번입니다"],
["16. 예제용 7번입니다"],
[" 111. 예제용 8번입니다"],
["01. 예제용 9번입니다"],
["A1. 예제용 10번입니다"],
[" 1. 예제용 11번입니다"],
[" 1예제용 11번입니다"]]
aa = "[시작][공백&숫자&영어:1~10] "
re_sql = jf.change_jf_sql_to_re_sql(aa)
print("정규표현식 구문은 ==>", re_sql)
for one in test_list:
result = jf.search(aa, one[0])
print(result)
원하는 것만 추출을 한 것입니다. 만약 변경을 하고싶다면 run_replase를 이용하시면 됩니다
하다가 생각난 부분인데, 위의 자료에서 공백이 2개 이상인 것을 1개의 공백으로 변경하도록 해보겠읍니다
그전에 앞뒤의 공백은 그냥 trim함수로 없애구요.
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_list = [
["2. 예제용 2번입니다"],
["3. 예제용 3번입니다"],
["4. 예제용 4번입니다"],
["5. 예제용 5번입니다"],
["6. 예제용 6번입니다"],
["16. 예제용 7번입니다"],
[" 111. 예제용 8번입니다"],
["01. 예제용 9번입니다"],
["A1. 예제용 10번입니다"],
[" 1. 예제용 11번입니다"],
[" 1예제용 11번입니다"]]
aa = "[시작][공백&숫자&영어.:1~15] "
re_sql = jf.change_jf_sql_to_re_sql(aa)
print("정규표현식 구문은 ==>", re_sql)
for one in test_list:
result = jf. replace_with_jf_sql
(re_sql, one[0], " ")
print(result)
생각보다 점(.)이 보기가 흉하네요. 그럼 점까지 없애는 방법을 넣은것입니다
"[시작][공백&숫자&영어:1~10] " 🡺 "[시작][공백&숫자&영어.:1~15] "
점(.)을 넣어서 점까지 선택이 되도록 하엿으며, 9번 예제는 공백을 포함하면 10글자이상되어서 15글자까지 검토를 하게하였더니 원하는 데로 나왔읍니다
예제 - 숫자나 영어소문자만 추출
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_text = """abcdef라고 ABCDEF도 소문자와 대문자를 함께쓴
abcdEFG쓰고(괄호1)로 만들고나서 숫자를 123456하고 789로 써본다.
숫자로 만 된 010-일이삼사-5678을 가지고 (괄호2)test해보려고 합니다
"""
jf_sql ="[영어소문자:1~]"
result = jf.search_all_with_jf_sql(jf_sql, test_text)
print("영어소문자만 찾는것 ===> ", result)
jf_sql ="[숫자:1~]"
result = jf.search_all_with_jf_sql(jf_sql, test_text)
print("숫자만 찾는것 ===> ", result)
예제 – 엑셀에서 셀값중 숫자만 뽑아내기

# -*- coding: utf-8 -*-
import xy_util, xy_excel, xy_color, xy_re
yt = xy_util.xy_util()
excel = xy_excel.xy_excel()
sc = xy_color.xy_color()
jf = xy_re.xy_re()
value_2d = excel.read_value_in_range("", [1,1,276,1])
jf_sql = "[숫자:1~]"
for x in range(len(value_2d)):
for y in range(len(value_2d[x])):
value = value_2d[x][y]
aa = jf.search(jf_sql, value)
print("찾은값 ==> ", aa)
if aa != []:
excel.write_value_in_cell("", [x + 1, 3], aa[0])
excel.write_value_in_cell("", [x + 1, 4], aa[-1])
for no in range(len(aa)):
excel.write_value_in_cell("", [x+1, 5+no], aa[no])
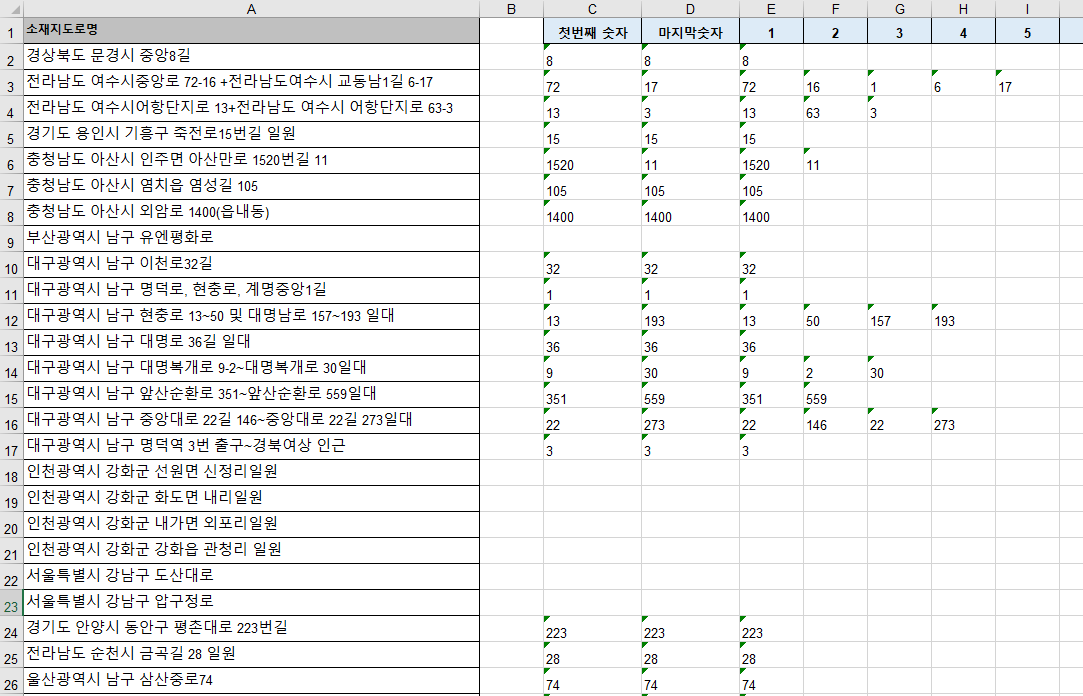
예제 - 숫자찾기
# -*- coding: utf-8 -*-
import jfinder
jf =jfinder.jfinder()
test_list = [
["2. 예제용 2번입니다"],
["3. 예제용 3번입니다"],
["4. 예제용 4번입니다"],
["5. 예제용 5번입니다"],
["6. 예제용 6번입니다"],
["16. 예제용 7번입니다"],
[" 111. 예제용 8번입니다"],
["01. 예제용 9번입니다"],
["A1. 예제용 10번입니다"],
[" 1. 예제용 11번입니다"],
[" 1예제용 11번입니다"]]
aa = "[시작][공백&숫자&영어.:1~15]"
re_sql = jf.change_jf_sql_to_re_sql(aa)
print("정규표현식 구문은 ==>", re_sql)
for one in test_list:
result = jf.search_all_with_re_sql(re_sql,one[0])
print(result)
예제 - 영어나 숫자만 찾기
# -*- coding: utf-8 -*-
import jfinder, youtil
jf =jfinder.jfinder()
util = youtil.youtil()
test_text = """abcdef라고 ABCDEF도 소문자와 대문자를 함께쓴
abcdEFG쓰고(괄호1)로 만들고나서 숫자를 123456하고 789로 써본다.
숫자로 만 된 010-일이삼사-5678을 가지고 (괄호2)test해보려고 합니다
"""
jf_sql ="[영어소문자:1~]"
result = jf.search_all_with_jf_sql(jf_sql, test_text)
print("영어소문자만 찾는것 ===> ")
util.print_one_by_one(result)
jf_sql ="[숫자:1~]"
result = jf.search_all_with_jf_sql(jf_sql, test_text)
print("숫자만 찾는것 ===> ")
util.print_one_by_one(result)
예제 - 숫자만 갖고오고싶은경우
# -*- coding: utf-8 -*-
import xy_re,xy_excel
jf =xy_re.xy_re()
excel = xy_excel.xy_excel()
# 어떤 셀값에서, 숫자만 갖고오고싶은경우가 있다
# 이럴때 사용하는 목적이며, 만약 숫자가 여러개이면, "."으로 구분하여 넣기
x1, y1, x2, y2 = xyxy = excel.read_address_for_selection()
list_2d = excel.read_value_in_range("",xyxy)
for index_x, list_1d in enumerate(list_2d):
for index_y, one_value in enumerate(list_1d):
searched_list_2d = jf.search_all_with_jf_sql("[숫자:0~][.:0~][숫자:1~]", one_value)
if searched_list_2d:
print(one_value, searched_list_2d, jf.concate_jfinder_result(searched_list_2d))
기본사용법
간단한 사용법을 보여드리겟습니다
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_text = """abcdef라고쓰고(괄호)로 만들고나서 숫자를 123456하고 789로 써본다.
숫자로 만 된 010-일이삼사-5678을 가지고 test해보려고 합니다
"""
aa = "[영어:1~10]" #문장중에서 영어로 연속된 1~10단어를 찾는것이다
result = jf.search(aa, test_text)
print(result)
예제 – 기본
위와 같은 메소드를 이용하여 자신이 원하는 것을 사용하시면 됩니다
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_str = "2. 예제용 2번입니다"
jf_sql = "[시작][공백&숫자&영어.:1~15]"
result = jf.search_all_with_jf_sql(jf_sql,test_str)
print("1. 결과는 => ", result)
jf_sql = "[한글:2~]"
result = jf.search_all_with_jf_sql(jf_sql,test_str)
print("2. 결과는 => ", result)
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_str = "문자만 있는 예제입니다"
jf_sql = "[시작][공백&숫자&영어.:1~15]"
result = jf.match_with_jf_sql(jf_sql,test_str)
print("1. 결과는 => ", result)
jf_sql = "[한글:1~15]"
result = jf.match_with_jf_sql(jf_sql,test_str)
print("2. 결과는 => ", result)
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_str = "문자만 있는 예제입니다"
jf_sql = "[시작][공백&숫자&영어.:1~15]"
result = jf.match_with_jf_sql(jf_sql,test_str)
print("1. 결과는 => ", result)
jf_sql = "[한글:1~15]"
result = jf.match_with_jf_sql(jf_sql,test_str)
print("2. 결과는 => ", result)
jf_sql = "[한글:1~15]"
result = jf.is_match_all(jf_sql,test_str)
print("3. 결과는 => ", result)
jf_sql = "[한글&공백:1~15]"
result = jf.is_match_all(jf_sql,test_str)
print("4. 결과는 => ", result)
jf_sql = "[한글&공백:1~15]"
result = jf.is_match(jf_sql,test_str)
print("5. 결과는 => ", result)
어디선가 자료를 갖고와보면 숫자번호가 메겨져있는 자료들이 있다 이것을 없애고 싶은 경우가 많다
| 바꿀것 | 간단 설명 |
| 1. 예제용 1번입니다 | 잘 입력이 된것 |
| 2. 예제용 2번입니다 | 잘 입력이 된것 |
| 3. 예제용 3번입니다 | 잘 입력이 된것 |
| 4. 예제용 4번입니다 | 잘 입력이 된것 |
| 5. 예제용 5번입니다 | 잘 입력이 된것 |
| 6. 예제용 6번입니다 | 잘 입력이 된것 |
| 16. 예제용 7번입니다 | 2자리숫자 |
| 111. 예제용 8번입니다 | 공백이 있고 3자리 숫자 |
| 01. 예제용 9번입니다 | 앞에 0자가 있는경우 |
| A1. 예제용 10번입니다 | 앞에 영문자가 있는경우 |
| 1. 예제용 11번입니다 | 공백뒤에 숫자가 있는경우 |
| 1예제용 11번입니다 | 공백이 있이고고 숫자가 있으면서 점이 없는경우 |
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_list = [
["2. 예제용 2번입니다"],
["3. 예제용 3번입니다"],
["4. 예제용 4번입니다"],
["5. 예제용 5번입니다"],
["6. 예제용 6번입니다"],
["16. 예제용 7번입니다"],
[" 111. 예제용 8번입니다"],
["01. 예제용 9번입니다"],
["A1. 예제용 10번입니다"],
[" 1. 예제용 11번입니다"],
[" 1예제용 11번입니다"]]
aa = "[시작][공백&숫자&영어:1~10] "
re_sql = jf.change_jf_sql_to_re_sql(aa)
print("정규표현식 구문은 ==>", re_sql)
for one in test_list:
result = jf.search(aa, one[0])
print(result)
| 결과값 |
| 정규표현식 구문은 ==> ^[\s\da-zA-Z]{1,10} [['2', 0, 1, [], <re.Match object; span=(0, 1), match='2'>]] [['3', 0, 1, [], <re.Match object; span=(0, 1), match='3'>]] [['4', 0, 1, [], <re.Match object; span=(0, 1), match='4'>]] [['5', 0, 1, [], <re.Match object; span=(0, 1), match='5'>]] [['6', 0, 1, [], <re.Match object; span=(0, 1), match='6'>]] [['16', 0, 2, [], <re.Match object; span=(0, 2), match='16'>]] [[' 111', 0, 4, [], <re.Match object; span=(0, 4), match=' 111'>]] [['01', 0, 2, [], <re.Match object; span=(0, 2), match='01'>]] [['A1', 0, 2, [], <re.Match object; span=(0, 2), match='A1'>]] [[' 1', 0, 7, [], <re.Match object; span=(0, 7), match=' 1'>]] [[' 1', 0, 7, [], <re.Match object; span=(0, 7), match=' 1'>]] |
하다가 생각난 부분인데, 위의 자료에서 공백이 2개 이상인 것을 1개의 공백으로 변경하도록 해보겠읍니다
그전에 앞뒤의 공백은 그냥 trim함수로 없애구요.
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_list = [
["2. 예제용 2번입니다"],
["3. 예제용 3번입니다"],
["4. 예제용 4번입니다"],
["5. 예제용 5번입니다"],
["6. 예제용 6번입니다"],
["16. 예제용 7번입니다"],
[" 111. 예제용 8번입니다"],
["01. 예제용 9번입니다"],
["A1. 예제용 10번입니다"],
[" 1. 예제용 11번입니다"],
[" 1예제용 11번입니다"]]
aa = "[시작][공백&숫자&영어.:1~15] "
re_sql = jf.change_jf_sql_to_re_sql(aa)
print("정규표현식 구문은 ==>", re_sql)
for one in test_list:
result = jf. replace_with_jf_sql
(re_sql, one[0], " ")
print(result)
| 결과값 |
| 정규표현식 구문은 ==> ^[\s\da-zA-Z.]{1,15} 2. 예제용 2번입니다 3. 예제용 3번입니다 4. 예제용 4번입니다 5. 예제용 5번입니다 6. 예제용 6번입니다 16. 예제용 7번입니다 111. 예제용 8번입니다 01. 예제용 9번입니다 A1. 예제용 10번입니다 1. 예제용 11번입니다 1예제용 11번입니다 |
"[시작][공백&숫자&영어:1~10] " 🡺 "[시작][공백&숫자&영어.:1~15] "
점(.)을 넣어서 점까지 선택이 되도록 하엿으며, 9번 예제는 공백을 포함하면 10글자이상되어서 15글자까지 검토를 하게하였더니 원하는 데로 나왔읍니다
예제 - 숫자나 영어소문자만 추출
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_text = """abcdef라고 ABCDEF도 소문자와 대문자를 함께쓴
abcdEFG쓰고(괄호1)로 만들고나서 숫자를 123456하고 789로 써본다.
숫자로 만 된 010-일이삼사-5678을 가지고 (괄호2)test해보려고 합니다
"""
jf_sql ="[영어소문자:1~]"
result = jf.search_all_with_jf_sql(jf_sql, test_text)
print("영어소문자만 찾는것 ===> ", result)
jf_sql ="[숫자:1~]"
result = jf.search_all_with_jf_sql(jf_sql, test_text)
print("숫자만 찾는것 ===> ", result)
| 결과값 |
| 영어소문자만 찾는것 ===> [['abcdef', 0, 6, [], <re.Match object; span=(0, 6), match='abcdef'>], ['abcd', 44, 48, []], ['test', 136, 140, []]] 숫자만 찾는것 ===> [['1', 56, 57, [], None], ['123456', 70, 76, []], ['789', 79, 82, []], ['010', 112, 115, []], ['5678', 121, 125, []], ['2', 134, 135, []]] |
# -*- coding: utf-8 -*-
import xy_util, xy_excel, xy_color, xy_re
yt = xy_util.xy_util()
excel = xy_excel.xy_excel()
sc = xy_color.xy_color()
jf = xy_re.xy_re()
value_2d = excel.read_value_in_range("", [1,1,276,1])
jf_sql = "[숫자:1~]"
for x in range(len(value_2d)):
for y in range(len(value_2d[x])):
value = value_2d[x][y]
aa = jf.search(jf_sql, value)
print("찾은값 ==> ", aa)
if aa != []:
excel.write_value_in_cell("", [x + 1, 3], aa[0])
excel.write_value_in_cell("", [x + 1, 4], aa[-1])
for no in range(len(aa)):
excel.write_value_in_cell("", [x+1, 5+no], aa[no])
예제 - 숫자찾기
# -*- coding: utf-8 -*-
import jfinder
jf =jfinder.jfinder()
test_list = [
["2. 예제용 2번입니다"],
["3. 예제용 3번입니다"],
["4. 예제용 4번입니다"],
["5. 예제용 5번입니다"],
["6. 예제용 6번입니다"],
["16. 예제용 7번입니다"],
[" 111. 예제용 8번입니다"],
["01. 예제용 9번입니다"],
["A1. 예제용 10번입니다"],
[" 1. 예제용 11번입니다"],
[" 1예제용 11번입니다"]]
aa = "[시작][공백&숫자&영어.:1~15]"
re_sql = jf.change_jf_sql_to_re_sql(aa)
print("정규표현식 구문은 ==>", re_sql)
for one in test_list:
result = jf.search_all_with_re_sql(re_sql,one[0])
print(result)
| 결과값 |
| 정규표현식 구문은 ==> ^[\s\da-zA-Z.]{1,15} [['2. ', 0, 3, [], <re.Match object; span=(0, 3), match='2. '>]] [['3. ', 0, 3, [], <re.Match object; span=(0, 3), match='3. '>]] [['4. ', 0, 3, [], <re.Match object; span=(0, 3), match='4. '>]] [['5. ', 0, 3, [], <re.Match object; span=(0, 3), match='5. '>]] [['6. ', 0, 3, [], <re.Match object; span=(0, 3), match='6. '>]] [['16. ', 0, 4, [], <re.Match object; span=(0, 4), match='16. '>]] [[' 111. ', 0, 6, [], <re.Match object; span=(0, 6), match=' 111. '>]] [['01. ', 0, 11, [], <re.Match object; span=(0, 11), match='01. '>]] [['A1. ', 0, 4, [], <re.Match object; span=(0, 4), match='A1. '>]] [[' 1. ', 0, 9, [], <re.Match object; span=(0, 9), match=' 1. '>]] [[' 1', 0, 7, [], <re.Match object; span=(0, 7), match=' 1'>]] |
# -*- coding: utf-8 -*-
import jfinder, youtil
jf =jfinder.jfinder()
util = youtil.youtil()
test_text = """abcdef라고 ABCDEF도 소문자와 대문자를 함께쓴
abcdEFG쓰고(괄호1)로 만들고나서 숫자를 123456하고 789로 써본다.
숫자로 만 된 010-일이삼사-5678을 가지고 (괄호2)test해보려고 합니다
"""
jf_sql ="[영어소문자:1~]"
result = jf.search_all_with_jf_sql(jf_sql, test_text)
print("영어소문자만 찾는것 ===> ")
util.print_one_by_one(result)
jf_sql ="[숫자:1~]"
result = jf.search_all_with_jf_sql(jf_sql, test_text)
print("숫자만 찾는것 ===> ")
util.print_one_by_one(result)
| 결과값 |
| 영어소문자만 찾는것 ===> ['abcdef', 0, 6, [], <re.Match object; span=(0, 6), match='abcdef'>] ['abcd', 44, 48, []] ['test', 136, 140, []] 숫자만 찾는것 ===> ['1', 56, 57, [], None] ['123456', 70, 76, []] ['789', 79, 82, []] ['010', 112, 115, []] ['5678', 121, 125, []] ['2', 134, 135, []] |
# -*- coding: utf-8 -*-
import xy_re,xy_excel
jf =xy_re.xy_re()
excel = xy_excel.xy_excel()
# 어떤 셀값에서, 숫자만 갖고오고싶은경우가 있다
# 이럴때 사용하는 목적이며, 만약 숫자가 여러개이면, "."으로 구분하여 넣기
x1, y1, x2, y2 = xyxy = excel.read_address_for_selection()
list_2d = excel.read_value_in_range("",xyxy)
for index_x, list_1d in enumerate(list_2d):
for index_y, one_value in enumerate(list_1d):
searched_list_2d = jf.search_all_with_jf_sql("[숫자:0~][.:0~][숫자:1~]", one_value)
if searched_list_2d:
print(one_value, searched_list_2d, jf.concate_jfinder_result(searched_list_2d))
기본사용법
간단한 사용법을 보여드리겟습니다
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_text = """abcdef라고쓰고(괄호)로 만들고나서 숫자를 123456하고 789로 써본다.
숫자로 만 된 010-일이삼사-5678을 가지고 test해보려고 합니다
"""
aa = "[영어:1~10]" #문장중에서 영어로 연속된 1~10단어를 찾는것이다
result = jf.search(aa, test_text)
print(result)
| 결과값 |
| [['abcdef', 0, 6, [], <re.Match object; span=(0, 6), match='abcdef'>], ['test', 87, 91, []]] |
위와 같은 메소드를 이용하여 자신이 원하는 것을 사용하시면 됩니다
# -*- coding: utf-8 -*-
import xy_re
jf =xy_re.xy_re()
test_str = "2. 예제용 2번입니다"
jf_sql = "[시작][공백&숫자&영어.:1~15]"
result = jf.search_all_with_jf_sql(jf_sql,test_str)
print("1. 결과는 => ", result)
jf_sql = "[한글:2~]"
result = jf.search_all_with_jf_sql(jf_sql,test_str)
print("2. 결과는 => ", result)
| 결과값 |
| 1. 결과는 => [['2. ', 0, 3, [], <re.Match object; span=(0, 3), match='2. '>]] 2. 결과는 => [['예제용', 3, 6, [], None], ['번입니다', 8, 12, []]] |
import xy_re
jf =xy_re.xy_re()
test_str = "문자만 있는 예제입니다"
jf_sql = "[시작][공백&숫자&영어.:1~15]"
result = jf.match_with_jf_sql(jf_sql,test_str)
print("1. 결과는 => ", result)
jf_sql = "[한글:1~15]"
result = jf.match_with_jf_sql(jf_sql,test_str)
print("2. 결과는 => ", result)
| 결과값 |
| 1. 결과는 => False 2. 결과는 => <re.Match object; span=(0, 3), match='문자만'> |
import xy_re
jf =xy_re.xy_re()
test_str = "문자만 있는 예제입니다"
jf_sql = "[시작][공백&숫자&영어.:1~15]"
result = jf.match_with_jf_sql(jf_sql,test_str)
print("1. 결과는 => ", result)
jf_sql = "[한글:1~15]"
result = jf.match_with_jf_sql(jf_sql,test_str)
print("2. 결과는 => ", result)
jf_sql = "[한글:1~15]"
result = jf.is_match_all(jf_sql,test_str)
print("3. 결과는 => ", result)
jf_sql = "[한글&공백:1~15]"
result = jf.is_match_all(jf_sql,test_str)
print("4. 결과는 => ", result)
jf_sql = "[한글&공백:1~15]"
result = jf.is_match(jf_sql,test_str)
print("5. 결과는 => ", result)
| 결과값 |
| 1. 결과는 => False 2. 결과는 => <re.Match object; span=(0, 3), match='문자만'> 3. 결과는 => False 4. 결과는 => True 5. 결과는 => <re.Match object; span=(0, 12), match='문자만 있는 예제입니다'> |